Case Study: Serverless architecture for The Ocean Cleanup
Earlier this year we completely rebooted the website of The Ocean Cleanup. In this case study we share some of the challenges we encountered, with their solutions.

The largest cleanup in history.
We’ve been involved with The Ocean Cleanup for a couple of years. We started out doing only design and front-end work, which was implemented in TYPO3 by a different agency.
This year however, we became their full digital partner, enabling us to revamp the technical architecture of the back-end.
We’re very proud of the work, and will share our choices in this article.
Assignment

Koen and Harmen volunteering for The Ocean Cleanup at The Interceptor™ launch event.
The Ocean Cleanup website is a fairly high traffic website. The previous site experienced more downtime than we deemed acceptable and suffered from heavy loads during visitor peaks. First and foremost, we wanted to make a sustainable choice for the architecture of this site. It had to be fast, but also reliable, being able to handle large spikes in traffic.
Furthermore, the team of The Ocean Cleanup is a tech-savvy bunch, who don’t shy away from administering rich content. A nice, clean CMS with rich content editing options is therefore required to enable them to create their content.
Old setup versus new setup
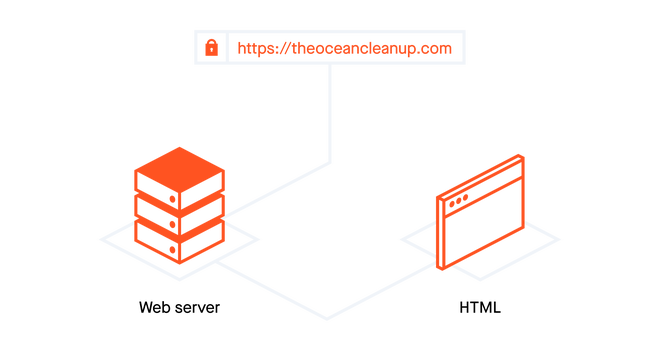
The legacy setup was a single-server setup.
Legacy setup
The old website was a classic setup: a single web server is responsible for serving the HTML, the CMS and all the rest.
Most websites on the internet are probably built like this – it’s how we’ve done it for years.
There’s some clear disadvantages however:
1. All your visitors, be they admin or general public, have to hit the same endpoint, beefing up the traffic together.
This restricts your choices. Your CMS probably doesn’t need the same performance as your public-facing website.
When they’re both served from the same endpoint, however, it’s hard to budget resources.
2. The server has to be a dynamic web server, using PHP or another server-side language to calculate and generate everything.
It might not be obvious what’s wrong with a dynamic web server. After all, there are a lot of server-side languages out there, are we saying they’re all inherently wrong?
Definitely not.
But in past years we’ve spent a lot of time tweaking database queries for performance, discussing all the various caching providers, or tuning our page rendering algorithms. These are valuable enhancements in a dynamic server setup, but when you completely flip this on its head, and switch to static HTML, all those problems don’t matter anymore.
There’s no bigger performance boost than completely bypassing a server-side language.
3. Tight coupling
Next to everything being literally close together (as in: living on the same server), it’s also tightly coupled technically. It’s hard to switch to another CMS but keep the templates, or to swap out the payment provider for donations but keep the CMS. All that code is part of one big monolithic system. When the CMS goes down, all services go down.
Being in this business for quite some time, we have a lot of first-hand experience with the downsides of tight coupling, in legacy projects of our own.
After supporting a site for years and years, your ability to change the software is directly related to the way various components are tied together.
When small changes require a complete system upgrade, your freedom to refactor is restricted.
We’ve been thinking of ways to separate concerns and practically divide the CMS from the templates, in order to be more agile when wanting to swap parts of the system.
New setup
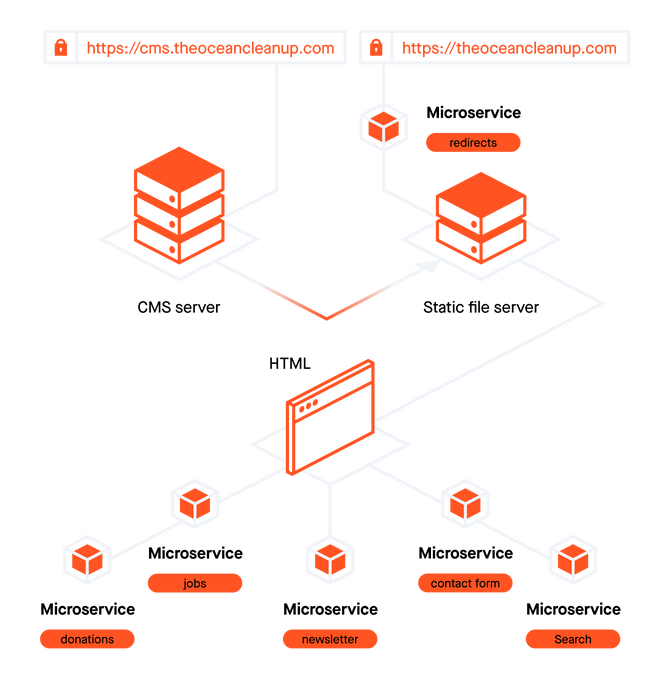
The new setup contains a lot more components, and most importantly separates the CMS from the public-facing website.
The CMS
For this project we’ve chosen a WordPress CMS. By employing plugins like Advanced Custom Fields we can offer the Ocean Cleanup team the rich editing experience they need to create great content.
💡 Koen has written extensively about our WordPress setup
Out of the box however, WordPress suffers from the same problems as outlined above: it’s a monolith, a CMS serving HTML as well.
We really wanted to use WordPress for its CMS-functionality, but not use it to serve content to visitors.
To overcome this, we wrote a plugin to generate a new build, consisting of all HTML pre-generated, and the required assets. This completely static version of the website is then uploaded to an Amazon S3 bucket.
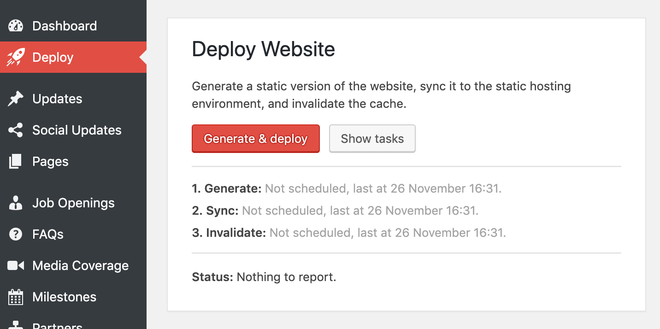
Admins can deploy the website themselves, right from the CMS.
Cronjobs are running on the CMS server to gather content from other sources, such as Salesforce, and trigger periodic builds and deploys programmatically to ensure data stays fresh.
Static web server
Separating the CMS server from the web server gives us a tremendous boost in performance, as well as resilience. We’ve installed CloudFront, Amazon’s content delivery network in front of the S3 bucket for fast worldwide delivery.
Since the bucket contains nothing but static HTML, it acts as a giant hard-drive that just looks up files, and nothing else. There’s no business logic, no database queries, no page rendering. It’s all there, ready to be served to your browser.
It will scale infinitely. It’s secure: by design there’s only public-facing content in the bucket – there’s nothing to hack. There are no OS upgrades that require us to upgrade PHP or WordPress, which might cause us having to rewrite the software or introducing bugs.
It’s just HTML.
Microservices
But what about the parts that just aren’t static?
Some parts of The Ocean Cleanup website are interactive. Applying for jobs, making donations, subscribing to the newsletter, are just some examples of actual dynamic actions you might take on the site.
We’ve separated these dynamic actions into microservices. Small, self-contained bits of software that we host on Amazon Lambda. These are small, fast, virtual machines that are booted in response to a request, so never idle.
We’ve written these microservices mostly in Laravel, and some in NodeJS. That’s one of the advantages of creating really small isolated bits of software – you can choose a technology that fits the problem, without worrying about compatibility with other pieces of software.
Interaction with the site
So how do these microservices fit in the larger plan? How do they work together with a static site?
We’ve been using Amazon’s APIGateway to tie certain HTTP endpoints to our Lambda functions. That way your function gets an endpoint that you can send requests to.
Most of the services we created work just like that: the static site contains a donation form, for example. Its action attribute points to the URL of the APIGateway, which calls the microservice with the formdata as payload. This is a traditional way of handling form submission.
Other services are called directly from client-side JavaScript, to update parts of the static DOM with dynamic data.
To not depend on JavaScript too much we tried to work with traditional forms and links as much as possible, pointing their action and href attributes to the APIGateway URL of the microservice.
This kept things simple, mostly, but also introduces its own class of problems.
For example, the maximum request payload for APIGateway is currently 10MB, but smaller at the time of development. This posed a problem for our job application form, in which applicants can upload their résumé.
A large file will be rejected by APIGateway with an unfriendly Amazon error page.
This was completely out of our control, because we were just sending the visitor along to Amazon’s servers. In this case we’ve chosen to upload the files using JavaScript directly to an S3 bucket, and send only the filename to our job application microservice.
Setup and deployment
Configuration of Amazon Web Services (AWS) can be pretty daunting. Even without taking all the different permissions, roles and groups into account it’s quite a hassle to setup your Lambda functions in concert with APIGateway.
We’ve looked at Amazon’s own SAM tool, but in the end went with the Serverless framework. It makes setup and deployment of microservices that much easier and more maintainable.
To work with PHP within the Lambda environment we’ve used Bref, a package for handling Lambda request payloads and responses. It also provides PHP runtimes to run your PHP Lambda functions.
In conclusion
The new architecture certainly looks daunting, and there are definitely more components at play.
But they are well separated, decoupled and work together robustly.
We’re also happy to have found a cost-effective solution for clients with low-traffic-occasional-peaks websites. These are the most difficult to budget for: clients with constant high traffic justifiably have to pay more for hosting. Consistent low traffic is easy as well, just pick a less expensive solution and you’re fine.
But we’ve got a lot of clients that are mostly low traffic, with occasional peaks due, for instance, to media attention. A less expensive solution can probably not handle these spikes, and paying a large sum year-round for hosting capacity is a waste of money and resources.
By sending all traffic to a CDN with simple, static HTML, we can provide for all these different types of clients.
Furthermore, this setup could serve very well in making websites with a lower carbon footprint. The CDN has to do significantly less work, and therefore consume less energy, than a traditional web server running PHP and a database.
Further development
Working with microservices brings its own host of problems which need tackling, such as:
- Deploying multiple dependent microservices together.
- Managing credentials for various microservices (with their staging and testing environments respectively).
- Service discovery: how will microservices call each other? Where are the endpoints stored?
- How do you share utility code between microservices?
Solving these problems is an ongoing effort and we keep fine-tuning our setup. With every serverless project we gain experience and have to solve unique problems.
One of the goals after all, was being able to detach and replace the various components without having to touch the other parts of the systems.
We love to share our work, so keep an eye on our GitHub profile for agnostic microservices, Serverless helpers, and more.